Science
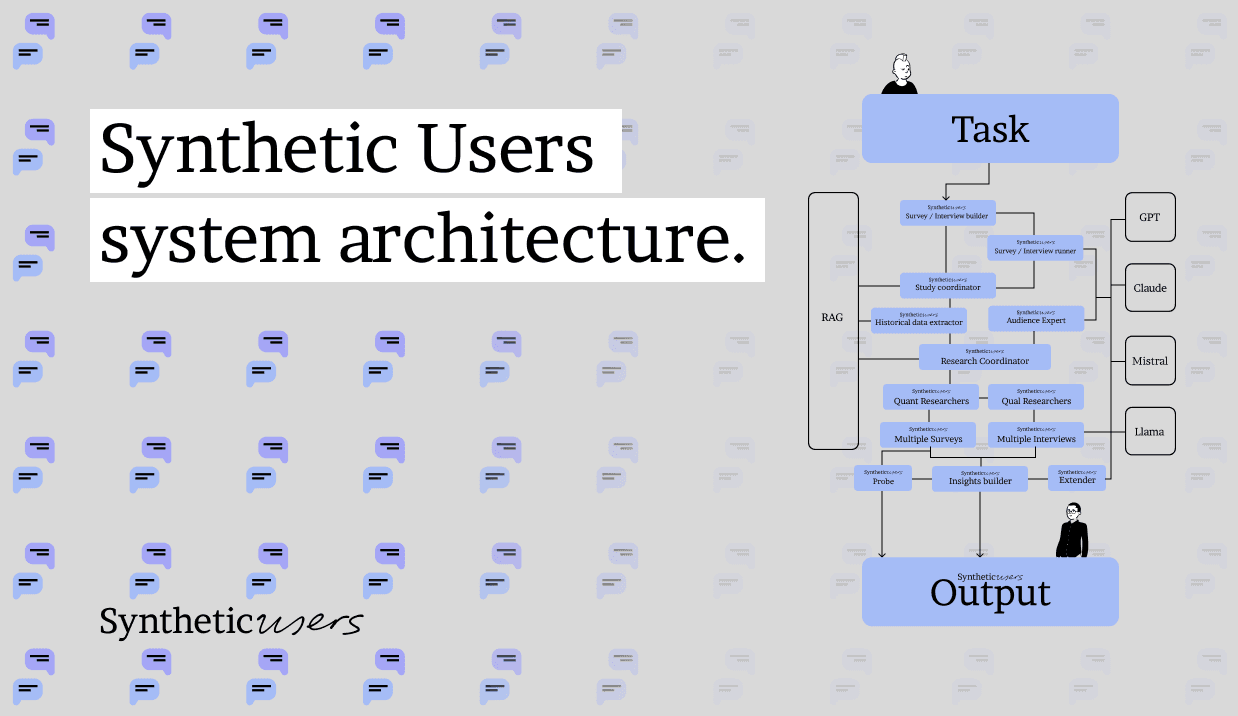
Synthetic Users system architecture (the simplified version).
Foundation models underpin Synthetic Users with advanced capabilities, enhanced by synthetic data and RAG layers for realism and business alignment, all within a collaborative multi-agent framework for richer interactions.
Foundation models underpin Synthetic Users with advanced capabilities, enhanced by synthetic data and RAG layers for realism and business alignment, all within a collaborative multi-agent framework for richer interactions.
TL;DR
But why shouldn't I go directly to a GPT like Claude, or Gemini? Because going straight to “a GPT” gives increasingly hyper-rational answers that don’t read like real (Organic) customers. People are smart, but they use shortcuts and are influenced by subconscious drivers. We fix that by:
routing across an ensemble of LLMs,
applying personality remapping (behavior → OCEAN) calibrated to real-world distributions,
grounding answers in your data via RAG, and
using specialized agents (Planner → Interviewer → Critic/Reviewer) with a feedback loop that tunes routing, prompts, and calibration over time. For why this isn’t “digital twins,” see Synthetic Users vs Digital Twins: https://www.syntheticusers.com/science-posts/synthetic-users-vs-digital-twins
Why this architecture (in one screen)
Multi-agent = better interviews. Different agents collaborate and critique, lifting realism and depth without hand-holding.
Ensemble over a single model. Models have different strengths and biases; routing/aggregation reduces skew and increases reliability.
Grounded in your data. RAG adds your facts at answer-time, so outputs stay specific and current without retraining.
Reality-checked. We benchmark against organic interviews (SOP) and encourage customers to run their own comparisons.
Not “digital twins.” We model behavioral spaces (traits × context × knowledge), not 1:1 replicas. It scales and stays fresh.
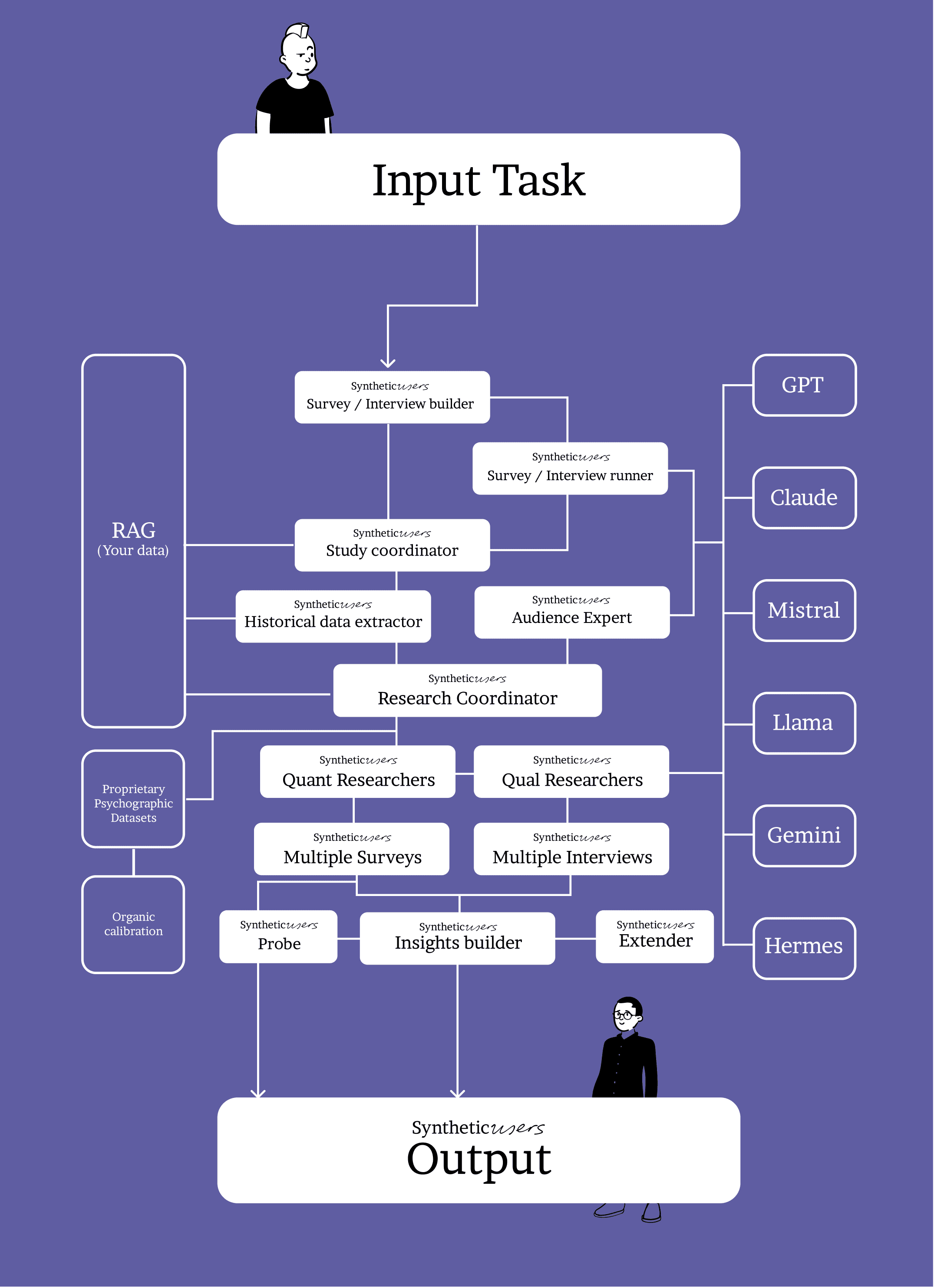
The pipeline (brief, practical) 1) Router + LLM ensemble
We’re model-agnostic. A lightweight router selects—and sometimes sequences—multiple LLMs (and can aggregate outputs). This hedges the failure modes of any single model and improves realism.
What you control: the task (“evaluate onboarding flow”), audience hints, and constraints (jurisdiction, tone, risk). What we adjust: model choice/order, temperature, aggregation, and guardrails.
2) Personality remapping (OCEAN-calibrated)
We don’t just generate a random OCEAN profile. We remap behavior to personality and calibrate to real populations:
Behavior → trait signals. We ingest proprietary behavioral datasets (e.g., purchasing frequency/recency, content categories viewed, session patterns) and map them to trait evidence.
Population calibration. We fit the resulting OCEAN distributions to match the real world for each target market/cohort. If our synthetic distribution drifts, we re-weight and remap.
Cohort priors. Geography, industry, and segment priors shift the sampling so your “Synthetic Users” resemble the actual mix of personalities you’d meet in that audience.
Per-study sampling. For each study, we sample personas so the set reflects the calibrated distribution (not just plausible one-offs).
Ongoing checks. We track coverage, drift, and parity against organic interviews and adjust remapping as needed.
Short version: OCEAN is the language, but calibration is the guarantee that our personalities line up with the organic world.
3) Your data via RAG (not fine-tuning)
At answer-time we retrieve facts from your interviews, surveys, CRM notes, product/docs and ground responses. No retraining required; updates flow through immediately. (Fine-tuning, when used, is separate and not required for grounding.)
4) Agents that do the work
Planner — turns your research goal into an interview plan.
Interviewer — runs the script, asks natural follow-ups, stays on brief.
Critic/Reviewer — checks realism, gaps, contradictions; triggers re-asks.
Router — optimizes LLM selection/ordering across the session.
Agents coordinate and learn from outcomes rather than relying on one monolithic prompt.
5) Feedback loop
We capture misses, contradictions, weak coverage, parity deltas, and calibration drift. That data updates routing, prompt templates, and personality remapping so interviews get sharper on your audience and edge cases.
Worked example (concrete)
Task: “Clinical interview with an oncologist in Berlin about trial enrollment UX.”
Router favors models strong on clinical context and formal tone.
Personality remapping samples a profile consistent with the real-world distribution for German hospital specialists (e.g., high conscientiousness, risk-aware, time-constrained), derived from our calibrated behavioral model.
RAG pulls your oncology guidelines, past interview notes, and relevant policy constraints.
Interviewer probes consent flow, eligibility filters, EMR hand-offs.
Critic flags missing questions on adverse-event reporting and multilingual support; re-asks.
Feedback updates routing and nudges remapping if we see systematic gaps for this cohort.
What this buys you
Speed: minutes to realistic interviews and to a solid report.
Coverage: multiple personas/contexts fast, without enumerating “twins.”
Change-tracking: when policies/copy change, RAG picks it up without retraining.
Bias control: ensemble + critic reduce single-model skew.
Reality checks: SOP comparisons keep us honest; calibration keeps personas aligned to the organic world.
RAG
The RAG layer plays a pivotal role in tailoring Synthetic Users to specific business needs by integrating domain-specific knowledge bases. This enables dynamic content generation that is both contextually relevant and aligned with business objectives.
The integration of RAG enhances the Synthetic Users' utility, ensuring that they serve as effective tools tailored to specific business requirements.
