
Science
Teaching Synthetic Users What Real People Actually Think
Synthetic Users without calibration are individually believable, but collectively wrong. The missing piece is calibration, not better models.

Synthetic Users without calibration are individually believable, but collectively wrong. The missing piece is calibration, not better models.
How we're grounding synthetic research in real-world sentiment.
When you ask an LLM to generate 20 synthetic users from Lyon, France, you don't get 20 Lyonnais. You get 20 reflections of the internet's aggregate opinion circa 2024. WEIRD-skewed, mode-collapsed, and frozen in time. If 55% of actual French citizens support a Gaza ceasefire, your synthetic population has no mechanism to know that, let alone reflect it. The personas feel plausible. The distribution is fiction, unless you put some work into it.
This is the core problem with synthetic user research as it's commonly practiced: the individuals are often believable, but the population is uncalibrated. And as three recent papers demonstrate, from very different angles, who you simulate determines what you find.
At Synthetic Users, we believe the solution isn't a better model. It's a better calibration stack.
The evidence
Park et al. (2023) built generative agents with memory, reflection, and planning. Twenty-five characters in a Sims-like town who autonomously spread party invitations, formed relationships, and coordinated activities. The architecture produces individually believable behavior. But there's no mechanism ensuring the 25 agents represent anyone in particular. They're fictional characters whose attitudes emerged from hand-authored seed descriptions, not from real population data.
Paglieri et al. (2026) attacked the opposite problem: population-level diversity. They showed that naive LLM prompting produces stereotypical clustering. Everyone sounds the same. Their evolved Persona Generators achieved 80%+ coverage across attitudinal dimensions, which is a significant technical achievement. But they explicitly optimize for support coverage (spanning what's possible), not density matching (reproducing what's probable). A population where half the users hold rare fringe views might score well on their metrics, but it would be useless for market research or sentiment modeling.
Kirk et al. (2024) provided the empirical proof that sample composition matters. PRISM's 1,500 participants from 75 countries, rating 21 LLMs across 8,011 conversations, revealed that model rankings shift by geography, demographic group, and topic. Sampling exclusively from one demographic reduced welfare for out-groups. Even the best-performing model only achieved roughly 45% preference. No single LLM satisfies everyone, and who you ask determines what you conclude.
The gap across all three: nobody built the bridge between real-world sentiment data and synthetic population generation.
That bridge is the calibration stack. And it's what we're building at Synthetic Users.
The architecture
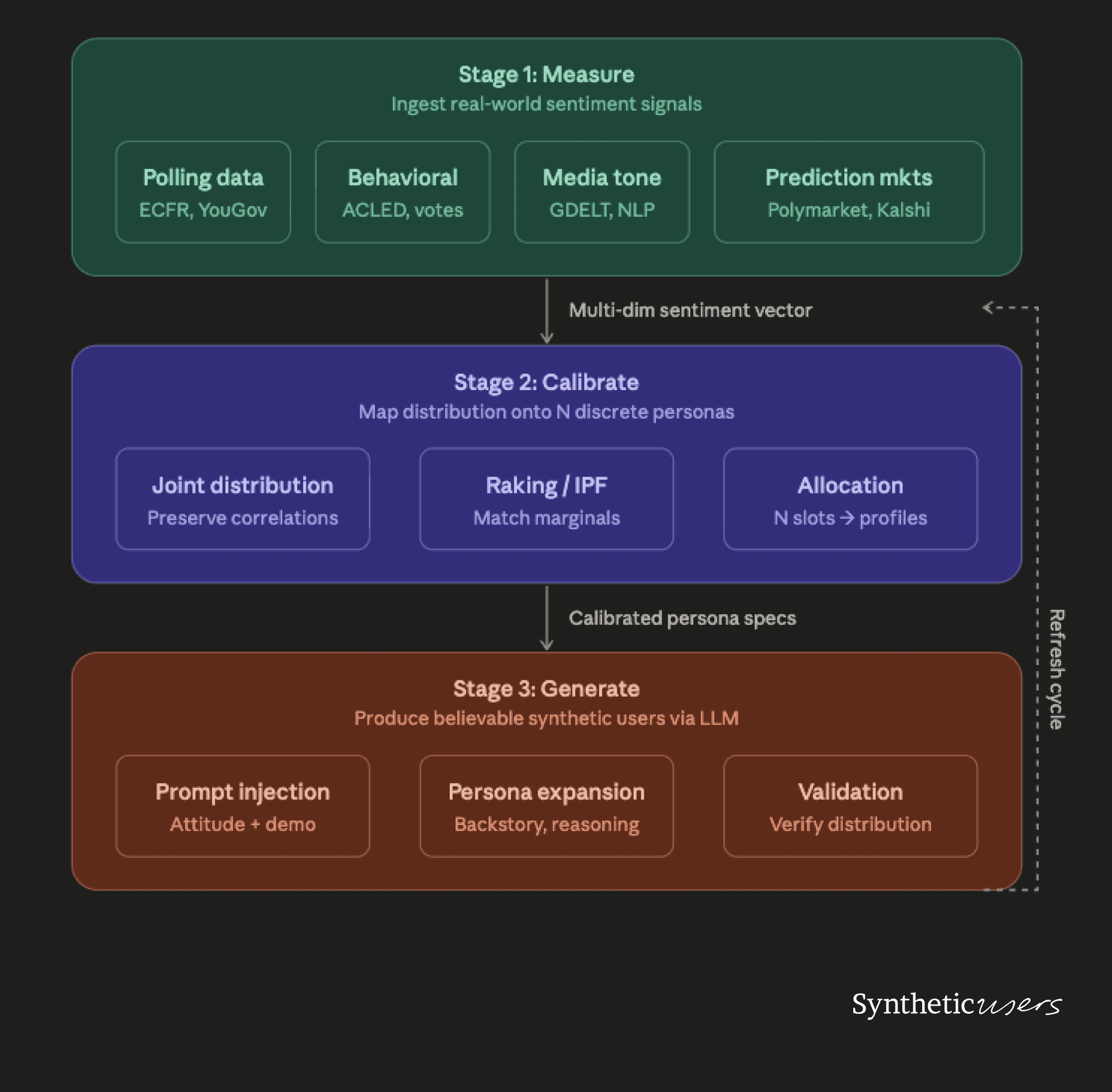
The calibration stack has three layers, each solving a distinct problem: Measure, Calibrate, Generate. Below each layer, we walk through the engineering choices that make it work.
Layer 1: Measure
The measurement layer ingests real-world attitudinal data and collapses it into a structured, multi-dimensional sentiment profile for a given region and topic. The key insight is that no single data source is sufficient. You need to triangulate across sources that operate at different temporal frequencies and capture different facets of sentiment.
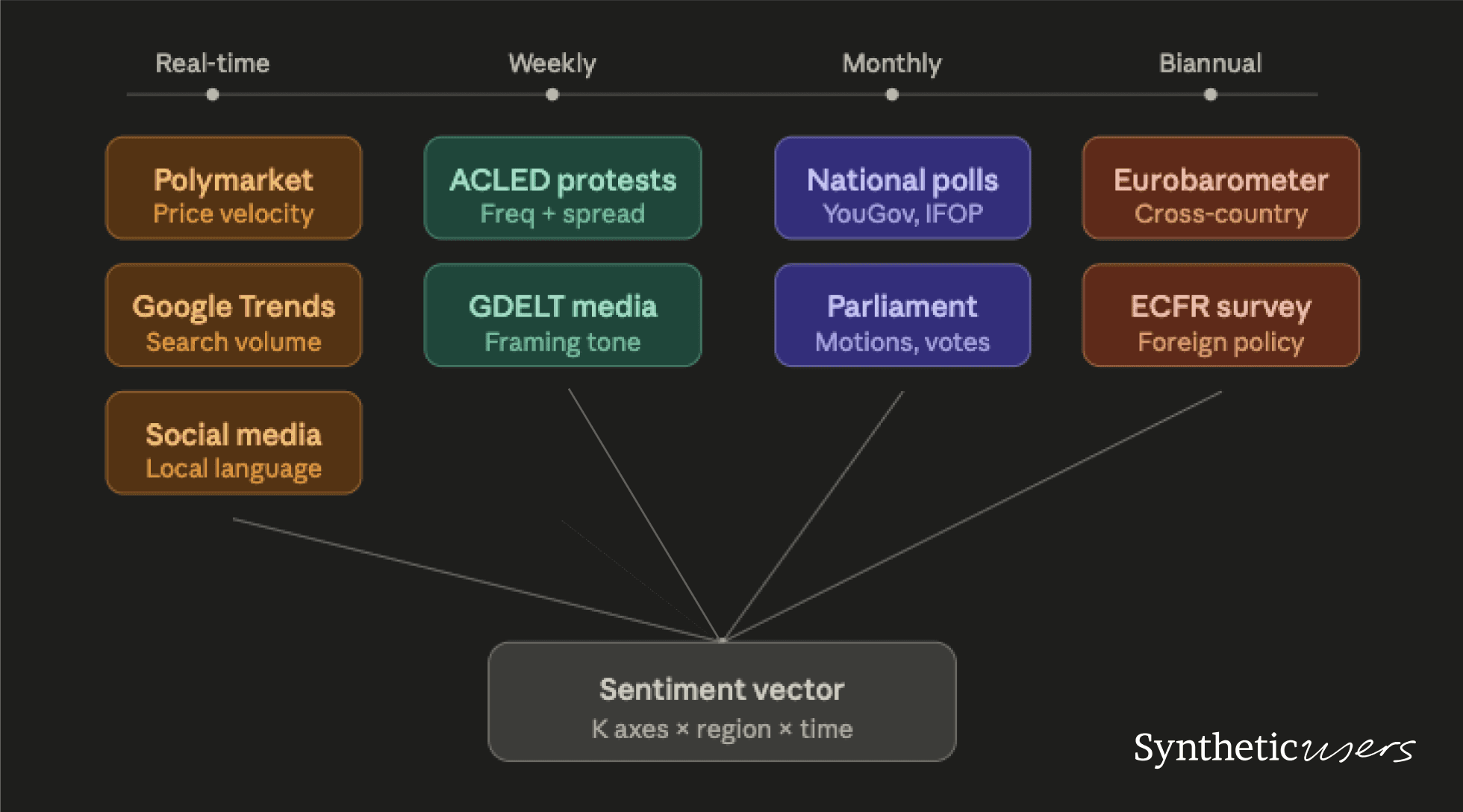
What the measurement layer produces: For a given region (say, France) and topic (say, Gaza ceasefire), the output is a multi-dimensional sentiment vector. Not a single number, but a structured profile across K attitudinal axes. For European sentiment toward Gaza, those axes might include stance on ceasefire, stance on arms exports, attitude toward humanitarian aid, trust in media narratives, and degree of engagement with the issue.
The critical design choice is temporal weighting. Fast-moving signals (prediction market price shifts, protest frequency spikes, social media volume) detect sentiment changes days or weeks before slow-moving signals (biannual Eurobarometer surveys, UN voting patterns) catch up. The system should use fast signals as leading indicators and slow signals as anchors. Trust the direction of movement from real-time data but calibrate the magnitude against more methodologically rigorous polling.
The data sources, by frequency:
Real-time (daily). Prediction markets like Polymarket and Kalshi provide price histories via public APIs. Google Trends captures search volume by country and language. Social media sentiment analysis, ideally in local languages (French Twitter, German TikTok), tracks volume and framing shifts.
Weekly. ACLED protest data provides geolocated, categorized records of demonstrations across Europe. GDELT's Global Knowledge Graph tracks media tone across thousands of outlets in near-real time.
Monthly. National polling firms fill the gaps between major surveys. YouGov (UK and expanding), IFOP and Elabe (France), Forsa (Germany), SWG (Italy). Parliamentary motion data and voting records capture elite positioning that both reflects and shapes public opinion.
Biannual. Eurobarometer provides cross-country comparisons with consistent methodology. The European Council on Foreign Relations (ECFR) runs pan-European foreign policy polling specifically designed to capture attitudes toward issues like Gaza.
The engineering challenge is normalization: converting heterogeneous data sources into a common attitudinal space. Each source measures something slightly different (search interest is not the same as stated opinion is not the same as revealed behavior), and the system needs explicit weights for how much to trust each signal type.
Layer 2: Calibrate
This is the hardest engineering problem in the stack. You have a continuous, multi-dimensional distribution from Layer 1, and you need to map it onto N discrete synthetic personas (say, 20) while preserving three properties that naive sampling destroys.
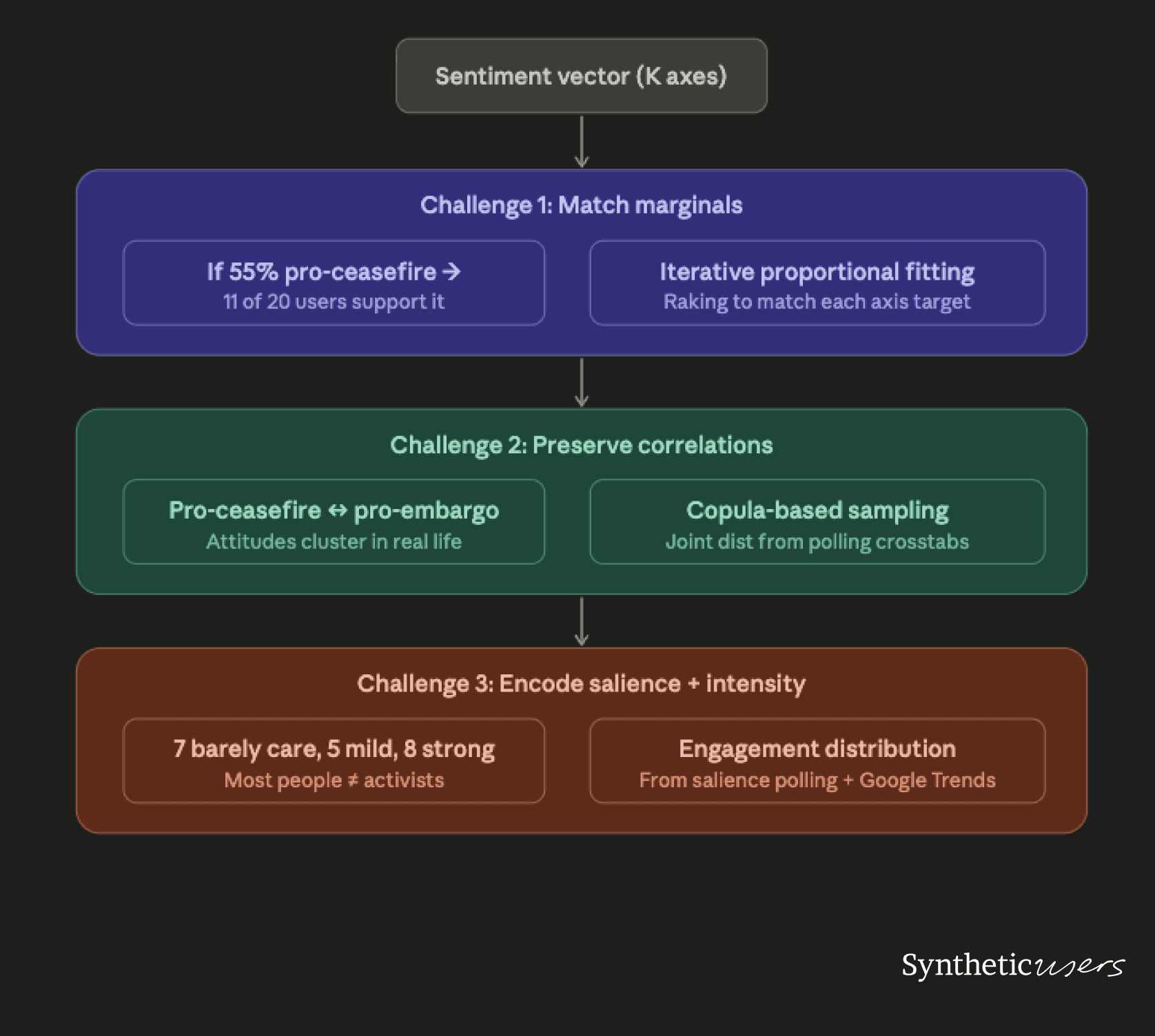
Challenge 1: Match the marginals. If 55% of the population supports a ceasefire, 11 of your 20 users should reflect that. If 70% are under 45, 14 of your 20 should be. This is the simplest requirement, and iterative proportional fitting (also called raking) handles it well. You start with an initial sample, then iteratively adjust weights until the marginal distribution on each axis matches the target.
Challenge 2: Preserve the correlations. This is where most synthetic population systems fail. Views on ceasefire, arms exports, humanitarian aid, and trust in institutions are correlated in complex ways that vary by country, age, and political affiliation. Sampling each axis independently produces incoherent people. Someone who strongly opposes a ceasefire but also strongly supports cutting arms to Israel doesn't exist in meaningful numbers.
The technical approach: build demographic archetypes from polling crosstabs. Most serious polls publish cross-tabulations showing how attitudes break down by age, gender, education, and political leaning. These crosstabs give you the conditional distribution of attitudes given demographics. Use copula-based sampling to generate attitude profiles that preserve the joint structure from these crosstabs while allowing natural variation within each demographic bucket.
Challenge 3: Encode salience and intensity. A person who "supports ceasefire" at 6/10 intensity behaves very differently from someone at 10/10. The 6 might not bring it up unprompted. The 10 might define their identity around it. And for most Europeans, Gaza isn't a top-five issue. Your synthetic population should reflect that.
This means your 20 personas might break down as: 7 who barely think about Gaza, 5 with mild opinions they'd share if asked, and 8 with strong views they'd volunteer. The "barely think about it" group is systematically underrepresented in most synthetic populations, but they're often the majority in real life. Salience data comes from Google Trends (search volume as a proxy for engagement), issue-importance questions in polls, and media consumption surveys.
The output of Layer 2 is a set of N structured persona specifications. Each contains a demographic profile, a position on each attitude axis (with intensity), a salience level, and a set of attitude correlations that are internally consistent.
Layer 3: Generate
The generation layer takes calibrated persona specs and produces rich, believable synthetic users via an LLM. This is where the architectural insights from Park et al. and Paglieri et al. become directly useful, but in service of a different objective.
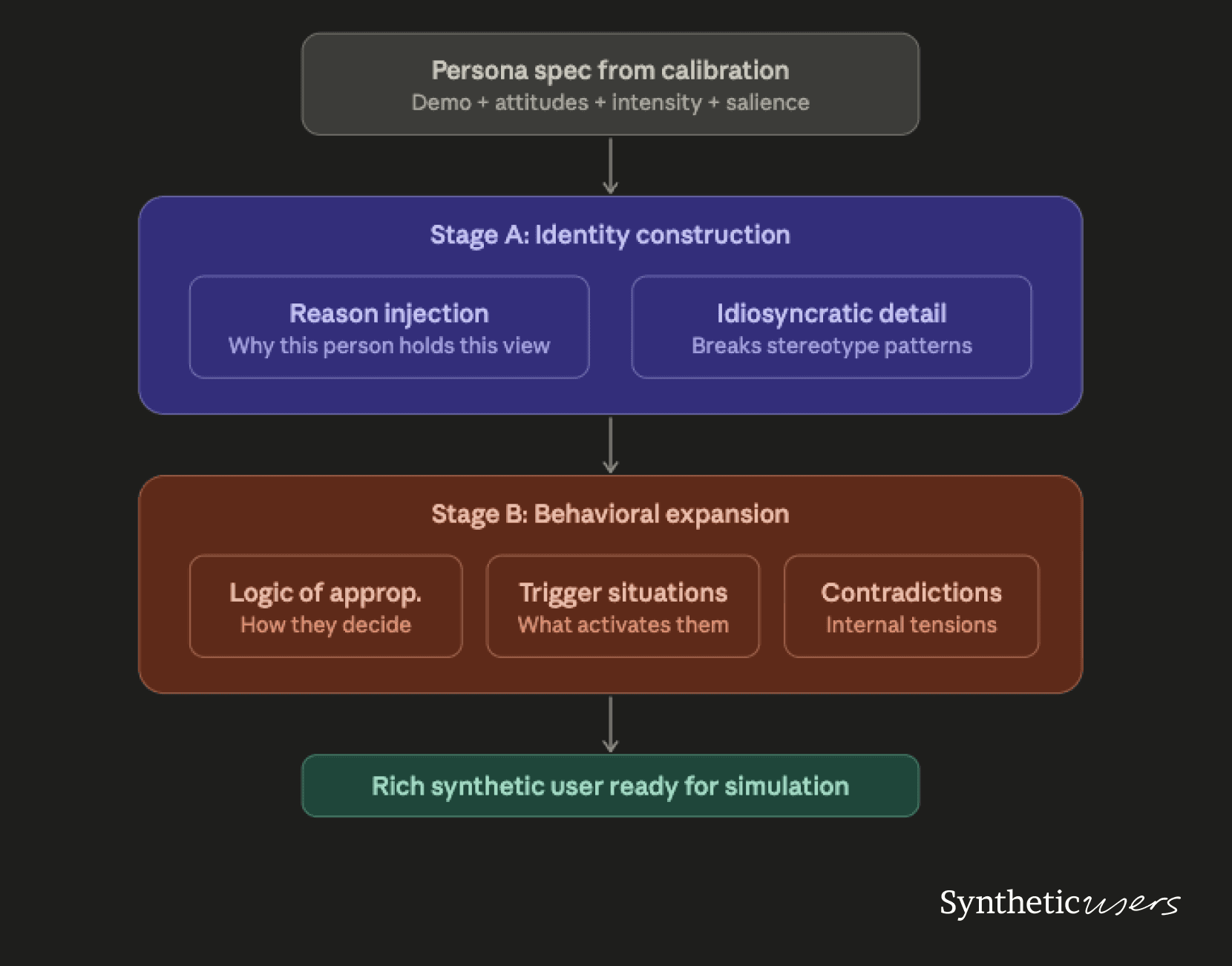
What the generation prompt should not do is simply label-stamp: "You are a 34-year-old French woman who supports a ceasefire." That produces a stereotype. What it should do is construct a person who holds that view for coherent, specific reasons.
Stage A: Identity construction. Give the persona a reason for their calibrated position that's consistent with their demographic profile. A 34-year-old French nurse who supports a ceasefire because she's seen medical colleagues volunteer in conflict zones holds the same position as a 34-year-old French teacher who supports it because her students include Palestinian families. Same attitude, different expression, different engagement pattern, different responses to counterarguments.
Critically, inject at least one idiosyncratic detail that doesn't perfectly track the archetype. Real people are inconsistent. A devout Catholic who supports abortion access. A climate activist who works in oil and gas. A right-wing voter who supports universal healthcare. These contradictions are the difference between a stereotype and a character.
Paglieri et al. found that formative-memory approaches (backstory-driven personas) were consistently outperformed by action-oriented approaches: personas defined by how they decide and act rather than what happened to them as a child. We've incorporated this into our generation pipeline.
Stage B: Behavioral expansion. Following the "logic of appropriateness" framework, expand the persona by answering three questions: What kind of situation is this? What kind of person am I? What does a person like me do in a situation like this? This gives the LLM a decision-making framework rather than a static description, which produces more diverse downstream behavior.
The best-performing generators in Paglieri et al.'s experiments produced first-person reasoning personas or rule-based behavioral descriptions, not third-person biographical sketches. We've adopted the same approach.
The refresh cycle
Static calibration degrades. The KellyBench study, where every frontier AI model lost money betting on Premier League matches over a full season, illustrates the failure mode: models given rich historical data but no mechanism for updating against a changing reality will systematically underperform. Your calibration stack needs a refresh trigger.
We recommend a dual-trigger architecture. Time-based refresh recalibrates weekly using the fastest signals in Layer 1. Event-based refresh recalibrates immediately when a fast signal crosses a threshold: a prediction market price shifting more than 10 points in 48 hours, or ACLED detecting a protest volume spike exceeding 2 standard deviations from the regional baseline. Event-based triggers catch sentiment shifts the moment they happen. Time-based triggers catch the gradual drift that no single event causes.
What this doesn't solve
We want to be direct about the limitations, because overconfidence here is worse than the problem itself.
The stated-vs-revealed preference gap. Both PRISM and Paglieri et al. found that what people say they believe and what they actually do can diverge. PRISM found weak correlations between survey-stated preferences and in-conversation behavioral preferences. Paglieri et al. found that questionnaire-based diversity only partially transferred to downstream behavioral diversity. Calibrating synthetic users' stated attitudes does not guarantee calibrated behavior. This is a fundamental limitation of any survey-grounded approach.
Correlation structure from sparse data. The copula-based sampling in Layer 2 requires polling crosstabs that many topics simply don't have. If no one has polled the joint distribution of ceasefire support, arms embargo support, and media trust for your specific region, you're estimating correlations from adjacent data or the LLM's priors. Be explicit about where the calibration data ends and the assumptions begin.
The ethical line. Kirk et al.'s PRISM paper argues that participation in AI feedback processes has intrinsic value as an act of justice. People should not only speak but be heard. Synthetic Users can approximate populations, but they cannot replace participation. A calibrated synthetic population is a prototyping tool and a scaling mechanism. It is not a democratic process. It should never replace direct consultation with the communities it claims to represent.
If you're using Synthetic Users to model how residents of a conflict zone feel about a ceasefire, you should be deeply aware of the epistemological distance between your simulation and their reality. The calibration stack narrows that distance. It does not eliminate it.
The punchline
Every paper in avaialble literature solves one piece of the puzzle. Park et al. proved that LLMs can produce believable individual agents with the right architecture. Paglieri et al. proved that evolutionary optimization can break through mode collapse to produce diverse populations. Kirk et al. proved that who you include in your sample determines what you find, and that no single model satisfies everyone.
None of them built the calibration stack that connects real-world sentiment data to synthetic population generation. That's the infrastructure that turns synthetic user research from an expensive hallucination into a useful tool.
The model is a commodity. The calibration stack is the product. And at Synthetic Users, that's exactly what we're building.